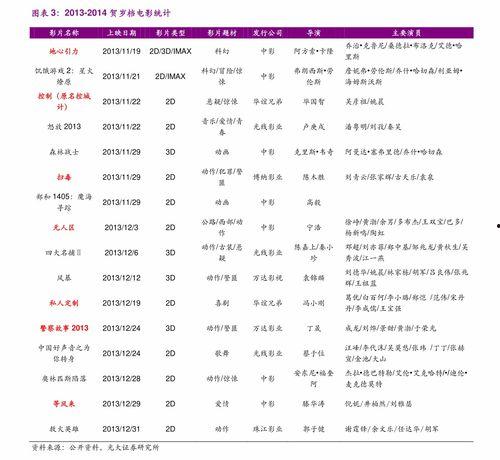
admin
admin
 admin
admin
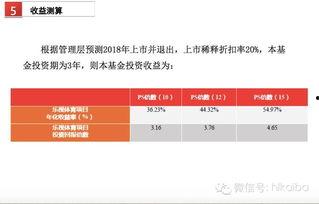 admin
admin
 admin
admin
 admin
admin
你知道吗?在七零年代,那可是个热闹非凡的时期呢!那时候,吃瓜群众可是无处不在,他们不仅见证了历史的变迁,还亲身参与了那个时代的风...

 admin2025-12-15
admin2025-12-15你有没有发现,最近网上那些吃瓜视频网站上的黑料视频越来越火了?咱们就来聊聊这个话题,看看这些视频背后都有哪些门道。吃瓜群众的新宠...
 admin2025-12-15
admin2025-12-15你知道吗?最近在网上有个地方可是火得一塌糊涂,那就是“独家爆料网免费爆料”啦!是不是听起来就让人心动?别急,让我带你一探究竟,看...

 admin2025-12-13
admin2025-12-13亲爱的读者们,今天我要给你带来一份超级大礼——热门大瓜每日必吃大瓜合集!在这个信息爆炸的时代,每天都会有各种新鲜事、爆炸性新闻层...

 admin2025-12-13
admin2025-12-13亲爱的读者们,今天我要给你带来一锅热腾腾的“吃瓜”大餐!在这个信息爆炸的时代,娱乐圈的瓜可是层出不穷,让人应接不暇。今天,就让我...

 admin2025-12-13
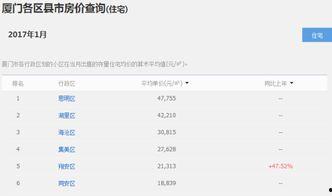
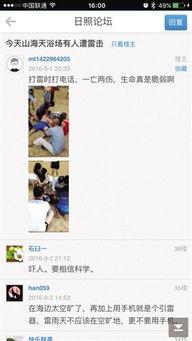
admin2025-12-13你知道吗?最近有个网站可是火得一塌糊涂,那就是9-1-1爆料网。这个网站就像一个巨大的信息宝库,里面藏着各种各样的秘密和爆料。今...
 admin2025-12-13
admin2025-12-13你有没有发现,最近你的朋友圈是不是也被一种表情包给刷屏了?没错,就是那个让人捧腹大笑的“吃瓜表情包”!今天,就让我带你来全方位揭...


 admin2025-12-13
admin2025-12-13你有没有听说最近超级火爆的综艺节目《明星大侦探》第四季终于可以免费观看完整版啦!没错,就是那个让你笑到肚子疼、猜到头秃的悬疑推理...


 admin2025-12-13
admin2025-12-13你知道吗?最近在互联网上可是掀起了一阵热潮,那就是关于那位在cj展会上大放异彩的美女。她不仅颜值爆表,而且才华横溢,让人忍不住想...


 admin2025-12-13
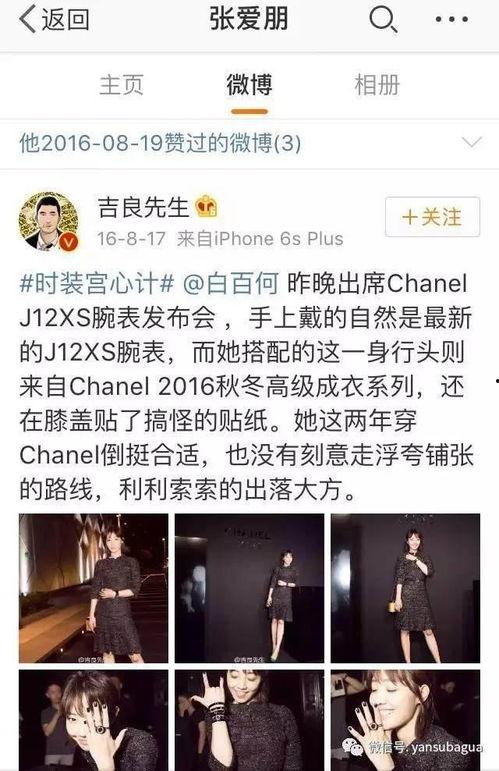
admin2025-12-13你知道吗?2025年的社会热点话题里,演艺圈明星系列长篇可是占据了不小的位置呢!这不,最近我可是挖到了一大堆关于明星们的八卦和趣...

 admin2025-12-13
admin2025-12-13